snappshop
Status
📜📞🔧❌
Senior Software Engineer (Golang)
Interview process
flowchart LR
sr(Send resume) --> hr(HR call) --> ti1(1st Technical Interview) --rejected--x ti2(2nd Technical Interview) -.-> hri(HR Interview) -.-> o(Offer)
Apply Way
Jobinja
Interview Date
-
Sent Resume
1403.06.03 -
HR Call
1403.06.09 -
Technical Interview
1403.06.10 AT 3 PM -
Rejection Email
1403.06.20
Interview Duration
- Technical Interview
1 hour & 30 minutes
Interview Platform
Skype
1st Technical Interview
سوالات سناریومحور و کنکوری بود. مثلا یه سناریو میگفت که در شرایط x چی کار میکنی؟ و هی از اون سناریو سوالات مختلف درمیاورد. نحوه برخورد و رفتار مصاحبهکننده اوکی بود و یه نفرم بود. نیم ساعت بیشتر از تایم ست شده طول کشید.
-
Tell me about yourself.
-
What are the differences between Go and Python? Compare these two languages.
- Performance
Go: Go is a compiled language, meaning the code is directly translated into machine code, which results in faster execution times. It is designed for high-performance tasks, making it suitable for building high-performance systems, networking applications, and cloud-native services.
Python: Python is an interpreted language, which means it’s slower than Go due to the overhead of the interpreter. However, Python’s performance can be enhanced by using external libraries or tools like Cython or PyPy. - Concurrency
Go: Go has built-in support for concurrency through goroutines and channels. Its concurrency model is one of the key reasons developers choose Go, as it simplifies writing concurrent programs and is ideal for systems with heavy multitasking.
Python: Python supports concurrency with threads and multiprocessing, but its Global Interpreter Lock (GIL) can be a bottleneck for CPU-bound tasks. Concurrency in Python can be more complex compared to Go. - Ease of Learning and Syntax
Go: Go has a simple and straightforward syntax, but it can feel more restrictive. Its simplicity is part of the language’s design, making it easier to understand for beginners, but it may require more boilerplate code.
Python: Python is known for its clean, readable, and concise syntax. It’s often recommended as a first programming language because of its simplicity and ease of learning, making it very popular for scripting, automation, and rapid application development. - Use Cases
Go: Go is optimized for backend systems, microservices, cloud infrastructure, and networking applications. It is widely used by companies like Google, Docker, and Kubernetes for building scalable, concurrent systems.
Python: Python excels in a wide range of areas, including web development (with frameworks like Django and Flask), data science, artificial intelligence, automation, and scripting. Its large ecosystem of libraries makes it a popular choice for scientific computing and data analysis. - Ecosystem and Libraries
Go: Go’s ecosystem is still growing, but it has a strong focus on performance and concurrency. The language has a standard library that’s robust for network programming, but it has fewer third-party libraries compared to Python. Python: Python has a massive ecosystem with a rich set of libraries and frameworks for virtually every domain, including data science (NumPy, Pandas), machine learning (TensorFlow, PyTorch), web development, and more. Python’s ecosystem is one of its greatest strengths. - Development Speed
Go: Go is designed to be simple and efficient, but it often requires more boilerplate code, which can slow down initial development compared to dynamic languages like Python.
Python: Python’s dynamic nature and extensive libraries allow for faster prototyping and development. It’s ideal for startups and projects where time-to-market is critical. - Memory Management
Go: Go has built-in garbage collection, but it is designed with manual optimizations to handle memory more efficiently than typical garbage-collected languages.
Python: Python also uses garbage collection, but its memory management is slower, making it less suitable for performance-critical tasks without optimization. - Error Handling
Go: Go has explicit error handling using multiple return values. This approach can be verbose but forces developers to handle errors explicitly, leading to more robust code.
Python: Python uses exceptions for error handling, which makes the code cleaner and easier to follow. However, it may encourage developers to overlook error cases until runtime. - Typing
Go: Go is statically typed, meaning types are checked at compile time. This adds safety, as many errors are caught before the program runs.
Python: Python is dynamically typed, making development faster and more flexible but also introducing the potential for runtime errors due to type issues. - Community and Support
Go: Go has a growing community, especially in cloud and infrastructure-related fields. It has strong backing from Google and is seeing increasing adoption.
Python: Python has one of the largest and most active programming communities, with extensive support for various use cases. Its community-driven development ensures frequent updates and improvements.
- Performance
-
How does memory management work in Go and Python?
In python:
realpython -
How does referencing work in Python, and how does it determine when to clean up references?
In Python, variables reference objects, and the language uses reference counting to manage memory. When an object’s reference count reaches zero (i.e., no variables point to it), the memory is freed. Additionally, Python has a garbage collector to handle circular references that reference counting can’t clean up. Cleanup happens automatically when reference counts drop or during periodic garbage collection.
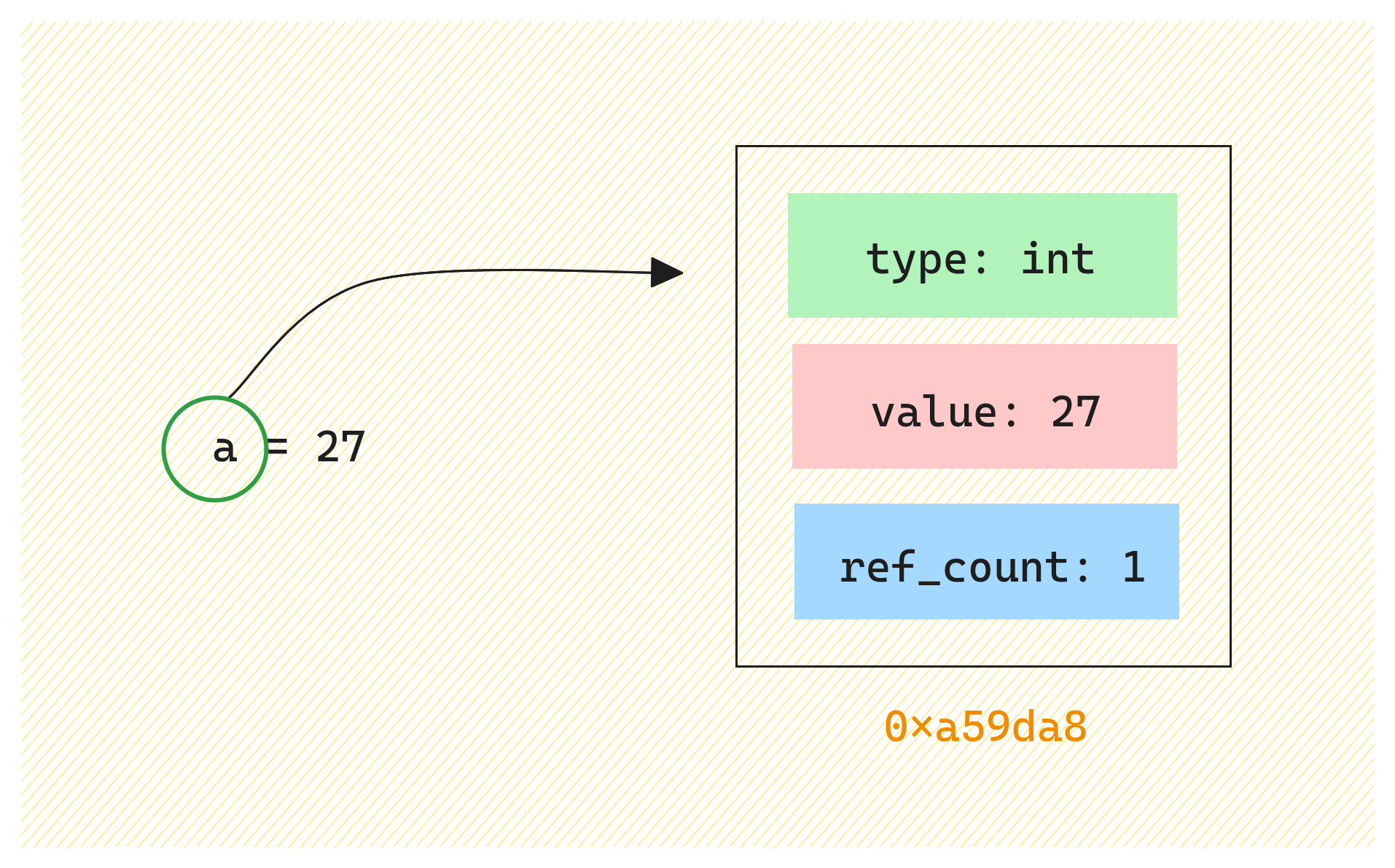
-
How does a Python project (django or fastapi) start up? How is it run from scratch?
-
In Python, how does a request reach our service?
- Client Request
A client (such as a web browser or an API client) sends an HTTP request to your service. This request includes information such as the HTTP method (GET, POST, etc.), headers, and any payload data. - Web Server
The request first reaches a web server (like Nginx or Apache) that is configured to listen for incoming HTTP requests. The web server may handle static files and forward dynamic requests to your Python application. - Application Server
The web server forwards the request to the application server, which runs your Python application. This can be done using WSGI (Web Server Gateway Interface) for frameworks like Flask or Django, or ASGI (Asynchronous Server Gateway Interface) for frameworks like FastAPI. - Framework Routing
Once the request reaches your Python application, the web framework processes it. The framework matches the incoming request’s URL and method to the defined routes (or endpoints) in your application. - Request Handling
The matched route handler (a function or method) is executed. This handler processes the request, which may involve: Validating input data. Interacting with a database or other services. Performing business logic. Preparing a response. - Response Generation
After processing, the handler generates an HTTP response, which includes a status code, headers, and the response body (e.g., HTML, JSON). - Returning the Response
The response is sent back through the application server to the web server, which then forwards it back to the client. - Client Receives Response
Finally, the client receives the response and can process it accordingly, such as rendering a webpage or displaying data.
- Client Request
-
What is the difference between
isand==in Python?The
isoperator checks for identity.
The==operator checks for equality.a = [1, 2, 3] b = a # b references the same list as a c = a[:] # c is a new list with the same content as a print(a is b) # True, because b is the same object as a print(a is c) # False, because c is a different object print(a == c) # True, because a and c have the same content -
We have two queries that are unrelated to each other. How do you run these and combine their data? Do you run one first and then the other or how?
Sequential Execution:
Run the first query, then the second, and combine the results. This is the simplest approach but may not be the most efficient.Asynchronous Execution in Python: This allows you to start both queries without waiting for the first to complete. Example:
python import asyncio async def run_query1(): # Query 1 logic here pass async def run_query2(): # Query 2 logic here pass async def main(): results = await asyncio.gather(run_query1(), run_query2()) # Combine results here asyncio.run(main())Goroutines in Go: Example:
func runQuery1(ch chan<- Result) { // Query 1 logic here ch <- result1 } func runQuery2(ch chan<- Result) { // Query 2 logic here ch <- result2 } func main() { ch := make(chan Result, 2) go runQuery1(ch) go runQuery2(ch) result1 := <-ch result2 := <-ch // Combine results here } -
We have a query that is too slow, how you try to fast it?
-
Analyze the Query Execution Plan
UseEXPLAIN: Run the query with theEXPLAINcommand (orEXPLAIN ANALYZEfor more detailed output) to understand how the database engine executes the query. This will provide insights into which indexes are being used, join methods, and where potential bottlenecks lie. Identify Slow Operations: Look for operations that have high costs, such as full table scans, large sorts, or expensive joins. -
Optimize Index Usage
Create Indexes: Ensure that appropriate indexes are in place for columns used inWHERE,JOIN,ORDER BY, andGROUP BYclauses. Review Existing Indexes: Check if existing indexes are being utilized effectively. Sometimes, redundant or unused indexes can slow down write operations. Consider Composite Indexes: If multiple columns are frequently queried together, consider creating composite indexes. -
Rewrite the Query
Simplify the Query: Break down complex queries into simpler sub-queries or Common Table Expressions (CTEs) to improve readability and performance. *Avoid SELECT : Instead of selecting all columns, specify only the columns you need. This reduces the amount of data processed and transferred. Use EXISTS Instead of IN: If applicable, usingEXISTScan be faster thanINfor subqueries, especially when dealing with large datasets. -
Optimize Joins
Check Join Conditions: Ensure that join conditions are using indexed columns. Limit the Number of Joins: If possible, reduce the number of joins or rearrange them to optimize performance. UseINNER JOINInstead ofOUTER JOIN: If you don’t need all rows from both tables, preferINNER JOINas it can be more efficient. -
Use Query Caching
Enable Query Caching: If your database supports it, enable query caching for frequently executed queries. This can significantly reduce execution time for repeated queries. -
Partition Large Tables
Table Partitioning: For very large tables, consider partitioning them based on certain criteria (e.g., date ranges). This can improve query performance by limiting the amount of data scanned. -
Optimize Database Configuration
Tune Database Settings: Review and optimize database configuration settings such as memory allocation, cache sizes, and connection limits based on your workload. -
Monitor and Analyze Performance
Use Monitoring Tools: Employ database monitoring tools to track query performance over time and identify trends or recurring issues. Log Slow Queries: Enable slow query logging to capture queries that exceed a certain execution time, allowing you to focus on optimizing the most problematic queries. -
Consider Denormalization
Denormalization: In some cases, denormalizing the database schema (i.e., combining tables) can improve performance for read-heavy applications, at the cost of increased complexity for write operations. -
Review Application Logic
Optimize Application Code: Sometimes, the issue may not be with the query itself but with how it is called from the application. Review the application logic to ensure that it is making efficient use of database queries.
-
-
Do you know ACID? What is A?
Atomicity in ACID refers to the property that ensures a series of operations within a transaction are completed fully or not at all. If any part of the transaction fails, the entire transaction is rolled back, maintaining data integrity.
-
What is index in database?
-
Is the list that holds pointers for rows in the database during indexing a list or another type of data structure?
No. Common data structures used for indexing are
B-Trees,Hash Tables,Bitmap IndexesandInverted Indexes. -
Why shouldn’t we index all columns? Doesn’t it become faster?
-
Increased Storage Requirements
While having more space might seem beneficial, each index consumes additional disk space. For large databases, this can lead to significant storage overhead, especially if many indexes are created on various columns that may not be frequently queried. -
Slower Write Operations
Every time a record is inserted, updated, or deleted, all associated indexes must also be updated. This can slow down write operations considerably. For databases with high transaction volumes, the overhead of maintaining numerous indexes can lead to performance bottlenecks. -
Index Maintenance Overhead
Indexes require regular maintenance to ensure they remain efficient. Over time, as data is modified, indexes can become fragmented, which can degrade performance. This maintenance can be resource-intensive, requiring additional processing time and effort. -
Diminished Query Performance
While indexes are designed to speed up read operations, having too many can lead to confusion for the query optimizer. The optimizer may struggle to determine which index to use for a given query, potentially leading to suboptimal execution plans and slower performance. -
Complexity in Query Optimization
With many indexes, the complexity of the query optimization process increases. The database management system (DBMS) must evaluate multiple indexes to determine the most efficient way to execute a query. This can lead to longer planning times and may not always result in the best performance. -
Reduced Performance for Certain Queries
Some queries may not benefit from additional indexes, particularly those that involve complex joins or aggregations. In such cases, the overhead of maintaining multiple indexes can outweigh the performance benefits, leading to slower overall query execution.
-
-
What is database isolation level?
-
What level is the isolation level of your company’s database?
-
The pod is not down, but you have an error (for example, error 500). How do you know where it comes from?
With Sentry.
-
How do you determine if an application is slow, and how do you measure it?
With Graphana.
-
What is the difference between multithreading and concurrency?
-
What is Docker?
-
What is the difference between Docker and VMs?
Virtualization Approach
VMs virtualize the hardware, running a complete operating system on top of virtual hardware. Each VM has its own OS, libraries, and applications.
Docker uses containerization, running applications in isolated user-space instances called containers. Containers share the host OS kernel and libraries.Resource Usage
VMs have higher overhead as each VM runs a full OS. They consume more memory and disk space.
Docker containers are more lightweight as they share the host OS. They start faster and have lower resource usage.Portability
VMs are portable across different hardware and cloud environments.
Docker containers are highly portable as they package the application with its dependencies. They can run consistently across different environments.Isolation
VMs provide strong isolation between the host and guest OS.
Docker provides process-level isolation between containers, but less isolation compared to VMs. -
What features does Linux have that Docker uses for isolated and separate operating systems and for running multiple isolated operating systems?
Namespaces
Purpose: Namespaces provide isolation for system resources, allowing Docker containers to have their own view of the system.
Types: Docker uses several types of namespaces, including:
PID Namespace: Isolates process IDs, so processes in containers do not see processes in other containers or the host.
Network Namespace: Provides each container with its own network stack, including IP addresses and routing tables.
Mount Namespace: Allows containers to have their own filesystem views, enabling them to mount different filesystems without affecting the host.
Control Groups (cgroups):
Purpose: Cgroups limit and prioritize the resource usage (CPU, memory, I/O, etc.) of containers.
Functionality: This ensures that one container cannot exhaust the resources of the host, providing a way to manage resource allocation among multiple containers.
Union File Systems:
Purpose: Union file systems allow Docker to create a layered file system, where images can share common layers.
Benefits: This reduces disk space usage and improves efficiency, as multiple containers can share the same underlying image layers while maintaining their own changes. -
What is the difference between hashing and encryption?
Hashing
Purpose: Hashing is primarily used for data integrity verification. It creates a fixed-size string (hash) from input data of any size, allowing for quick comparisons to verify that the data has not changed.
One-Way Function: Hashing is a one-way process, meaning that it is not designed to be reversible. Once data is hashed, it cannot be converted back to its original form.
Deterministic: The same input will always produce the same hash output, which is useful for checking data integrity.
Common Algorithms: Examples of hashing algorithms include SHA-256, MD5, and SHA-1.
Use Cases: Hashing is commonly used in password storage, data integrity checks, and digital signatures.
Encryption
Purpose: Encryption is used to protect data confidentiality. It transforms readable data (plaintext) into an unreadable format (ciphertext) to prevent unauthorized access.
Two-Way Function: Encryption is a reversible process. Encrypted data can be decrypted back to its original form using a key.
Key-Based: Encryption relies on keys for both the encryption and decryption processes. Different keys can produce different ciphertexts from the same plaintext.
Common Algorithms: Examples of encryption algorithms include AES (Advanced Encryption Standard), RSA, and DES (Data Encryption Standard).
Use Cases: Encryption is used in secure communications, data protection, and secure storage solutions. -
What hashing algorithm do you use?
SHA256
-
What is difference between RSA and AES?
-
If you have multiple users with the same password, resulting in identical hashes, and you want to ensure that their records in the database are unique, what can you do to make the records unique?
Use Salted Hashes
-
What is difference between channel and connection in rabbitMQ?
-
We have a table with three fields: start time, end time and ID. This is too slow. How do you try to speed it up?
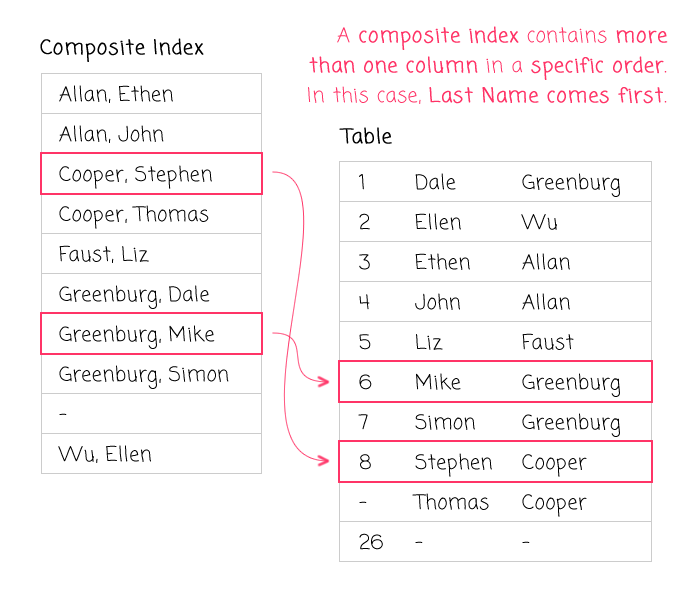
-
We have two consumers and there are a hundred messages in the queue (RabbitMQ). The first one takes all of them. What should we do so that the second one also receives some?
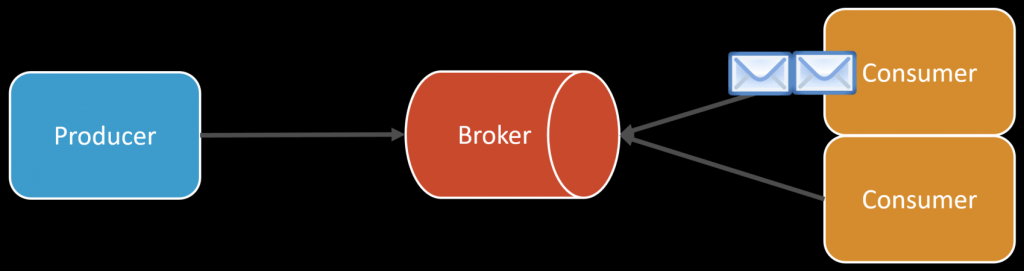
Ensure that your consumers are configured to use fair dispatch. This means that RabbitMQ will distribute messages more evenly between consumers. You can achieve this by setting the prefetch count to a lower value, which allows each consumer to receive a limited number of messages at a time. For example: python:
channel.basic_qos(prefetch_count=1) -
We execute a query for successful user transactions and send a message to RabbitMQ to trigger an SMS. What do you do if RabbitMQ is down?
However, for this specific scenario, the Outbox pattern is indeed an excellent solution.
And you can:- Implement a retry mechanism:
We can use a library like Spring Retry to automatically retry sending the message to RabbitMQ after a short delay. This can help handle temporary network issues or brief RabbitMQ outages. - Use a local queue or database:
If RabbitMQ is unreachable, we can store the messages in a local queue or database table. A background job can then periodically attempt to resend these messages to RabbitMQ once it’s back online. - Circuit breaker pattern:
Implement a circuit breaker (like Hystrix) to prevent repeated failed attempts to reach RabbitMQ, which could overload our system or RabbitMQ when it comes back online. - Fallback mechanism:
Have a backup notification system in place. For example, we could directly call an SMS API if RabbitMQ remains unavailable after several retry attempts. - Logging and monitoring:
Ensure all failed attempts are logged for later analysis. We should also implement alerts to notify our operations team of RabbitMQ downtime. - Message persistence:
Store critical messages to disk before attempting to send them to RabbitMQ. This ensures no data is lost even if our application crashes. - Use RabbitMQ in a cluster:
If high availability is crucial, we could set up RabbitMQ in a cluster configuration to minimize downtime. - Implement a dead letter queue:
Messages that repeatedly fail to be published can be moved to a dead letter queue for later manual processing or investigation.
- Implement a retry mechanism:
-
How you fix merge conflict?
-
What is difference between git Merge and Rebase?
-
What is fast-forward?
-
What was your git flow at your previous company?
-
Any questions?
I want to know about your teams, your company, your state, and things like these.
Score
7/10
همانطور که سنگ بزرگ نشانه نزدنه، سوالات زیاد در مصاحبه هم نشانه ریجکتی. سوالات خوب بود ولی تو ماچ بود.